
Caching data in Node.js application with Redis


Caching is the process of storing frequently accessed data to serve them quickly when needed. It reduces the response time of service and a load of requests to handle by a service. You need a caching solution when your service receives many requests and the data requested doesn't change much.
There are many types of caching: Application Caching, Database Caching, DNS Caching, Client-Side Caching, CDN Cache, and API Gateway Cache.

This post focus on implementing data caching to improve the responsiveness of a web application and reduce calls to the database.
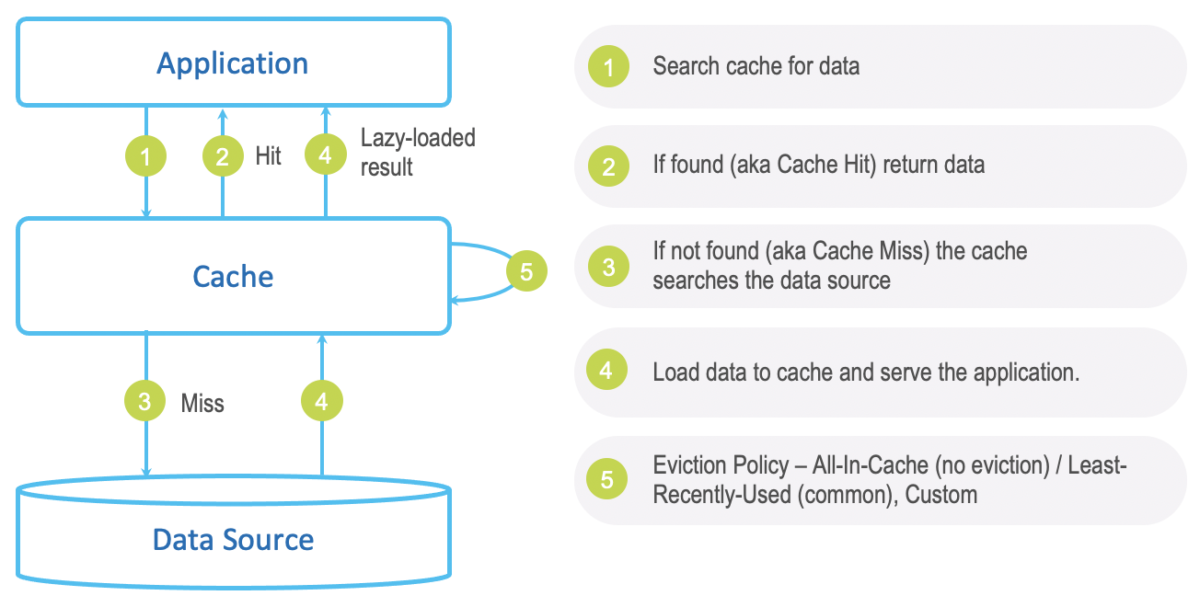
Picture found at: https://www.gigaspaces.com/blog/in-memory-cache/
The use case
You have an electronic e-commerce website where users can browse all the products or search for a specific product using some criteria. As the business grows, your products catalog also increases, more users search for products on your website, and your server struggles to serve the requests.
Yet, the search made by users is often similar in terms of criteria; hence, it produces the same result, but your server still has to process each request.
We can store the search result in an In-Memory database; when a request with the criteria comes in, the computed result is sent to the client.
We will see how to solve this problem using Redis in a Node.js application.
Prerequisites
You need these tools installed on your computer to follow this tutorial.
- Node.js 20.6+ - I wrote about installing Node.js
- A Node.js Package Manager - I will use Yarn
- Docker - Download's link
We need Docker to run two containers for Redis and MySQL, respectively.
Set up the Redis instance
Run the command below to start a Docker container from the Redis image you can find in the Docker Hub.
docker run -d -p 6379:6379 --name redisdb
Set up the project
I prepared a Node.js project with the endpoints we need so we can focus on data caching. Before cloning the project, start the Docker container from the MySQL image that the project will connect and store the data.
docker run -d -e MYSQL_ROOT_PASSWORD=secret -e MYSQL_DATABASE=product-inventory --name mysqldb -p 3307:3306 mysql:8.0
Let's clone the project from the GitHub repository and setup locally:
git clone https://github.com/tericcabrel/node-caching.git
cd node-caching
yarn install
yarn db:seed
yarn startThe command yarn db:seed will load the database with 05 categories and 32 products.
The application will start on port 8030. Here are the endpoints of the application:
| Endpoint | Method | Parameters |
|---|---|---|
| /categories | GET | Retrieve all categories |
| /products | GET | Retrieve all products |
| /products/search | GET | Search products by name, category, price, and availability |
| /products | POST | Add a new product |
Test the endpoint
The request to the endpoint /products and /products/search take at least 03 seconds to complete because I added a sleep of 3 seconds in the file src/controllers/product.controller.ts to simulate the server pressure and high computation.
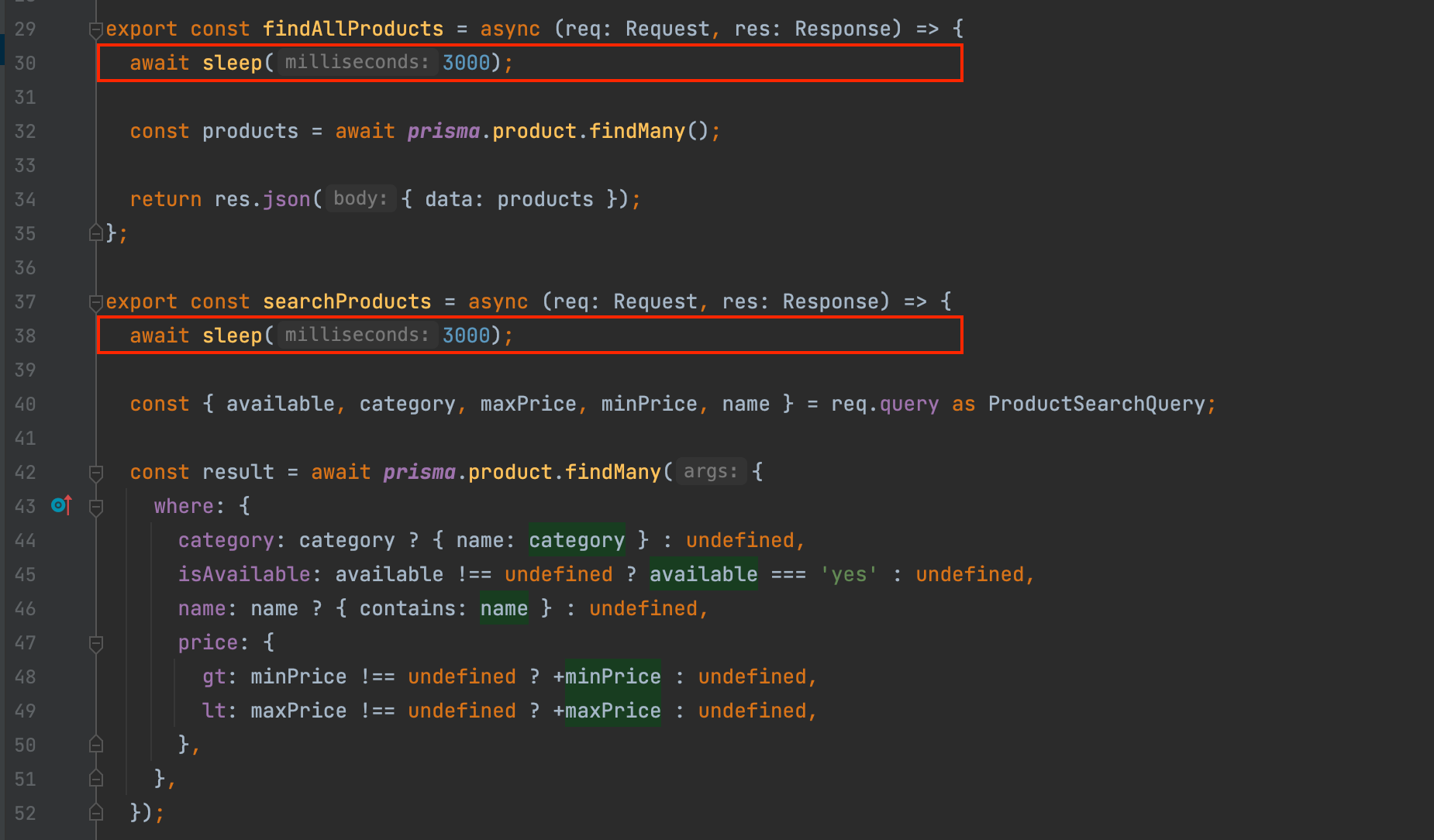
Now we will update the application so that the request hits the database only if the data to retrieve doesn't exist in the cache.
Configure Redis in Node.js
We need a Redis client for Node.js to interact with the Redis server. We will use the Node package called ioredis. Let's install it:
yarn add ioredis
Update the .env file to define the credentials for connecting to the Redis instance from the Node.js application:
REDIS_HOST=localhost
REDIS_PORT=6379
Create a file src/utils/redis.ts and add the code below:
import Redis from 'ioredis';
const REDIS_HOST = process.env.REDIS_HOST ?? 'http://localhost';
const REDIS_PORT = parseInt(process.env.REDIS_PORT ?? '6379', 10);
const redis = new Redis(REDIS_PORT, REDIS_HOST);
export { redis };
Cache the request
We have two endpoints to cache the data; the first one to cache is the one to retrieve all the products in the database.
To store data in Redis, you need a unique key to identify it. This ensures you don't duplicate data.
Cache the route /products
Update the function findAllProducts of this endpoint in the file product.controller.ts:
export const findAllProducts = async (req: Request, res: Response) => {
const CACHE_KEY = 'allProducts';
const rawCachedData = await redis.get(CACHE_KEY);
if (rawCachedData) {
const cachedData = JSON.parse(rawCachedData) as Product[];
return res.json({ data: cachedData });
}
await sleep(3000);
const products = await prisma.product.findMany();
redis.set(CACHE_KEY, JSON.stringify(products));
return res.json({ data: products });
};Re-run the application and test the endpoint:
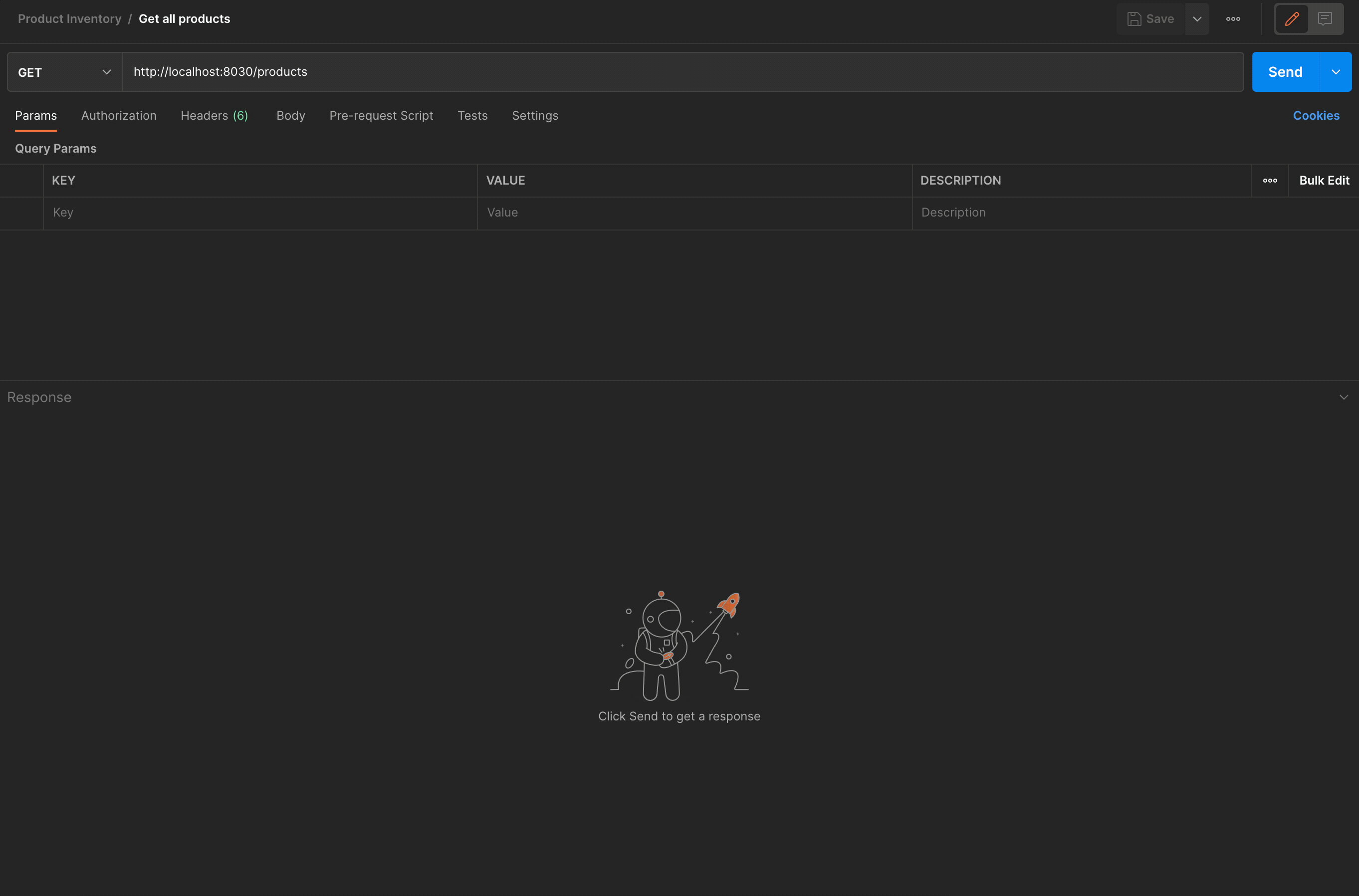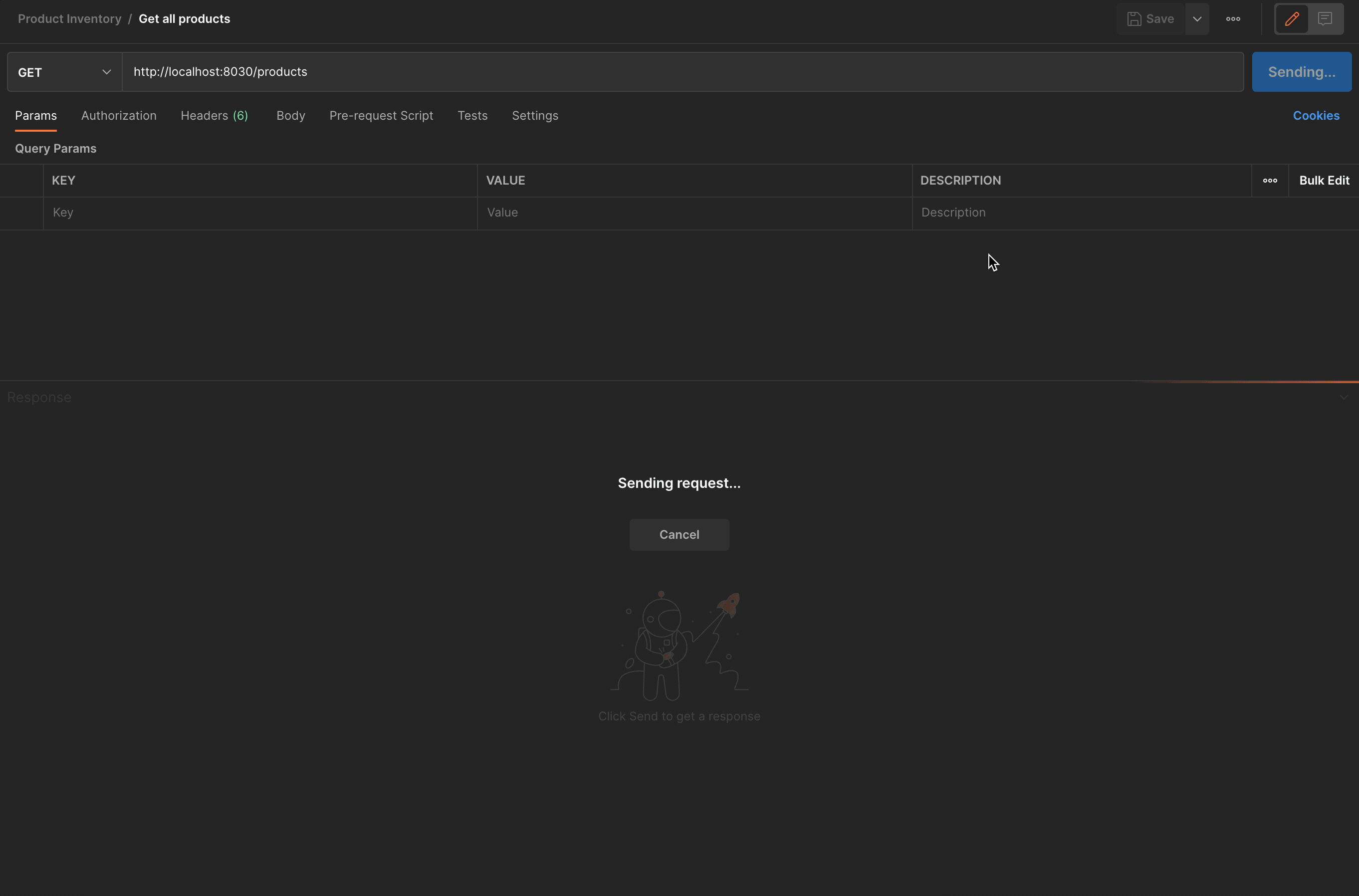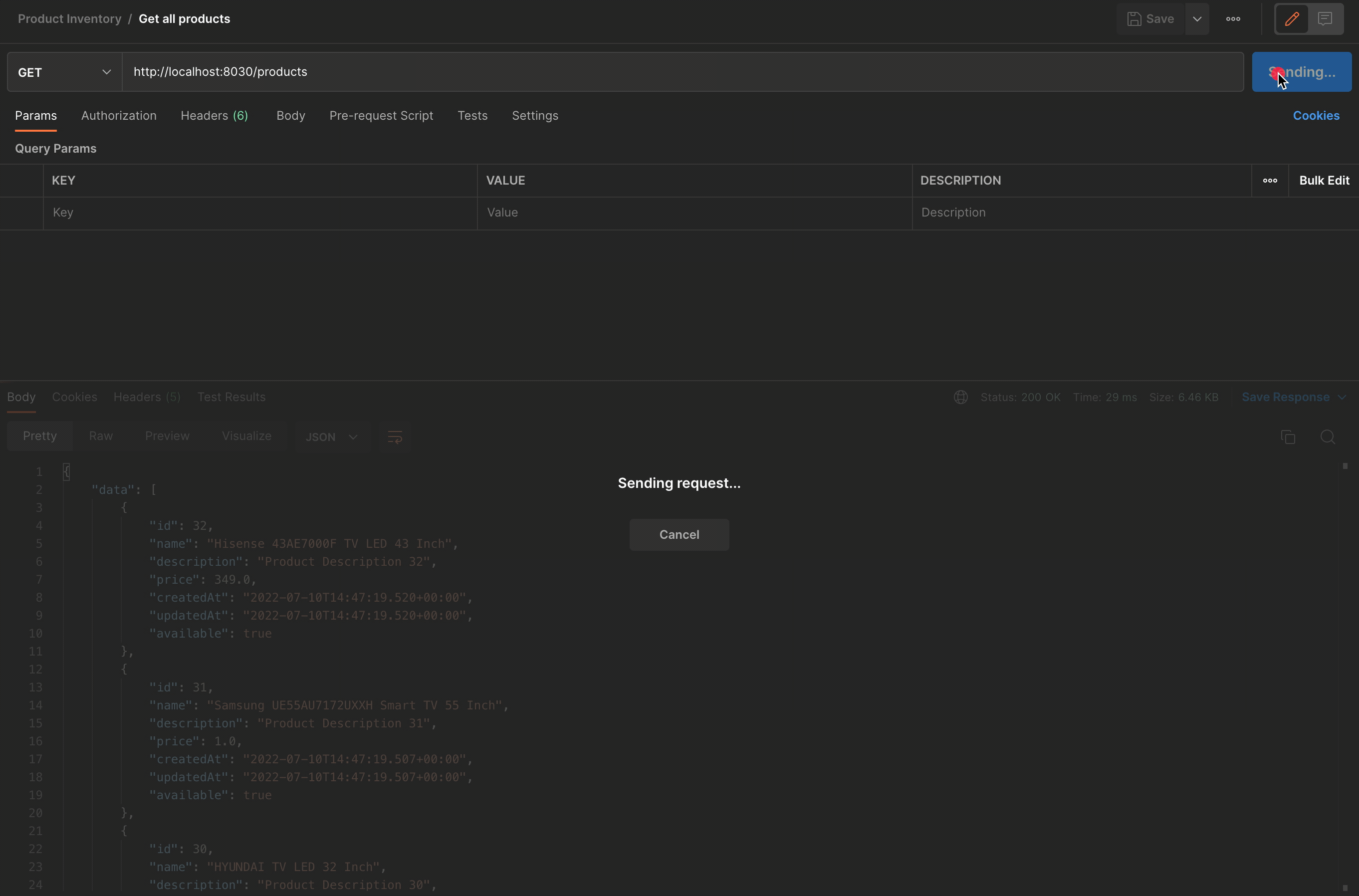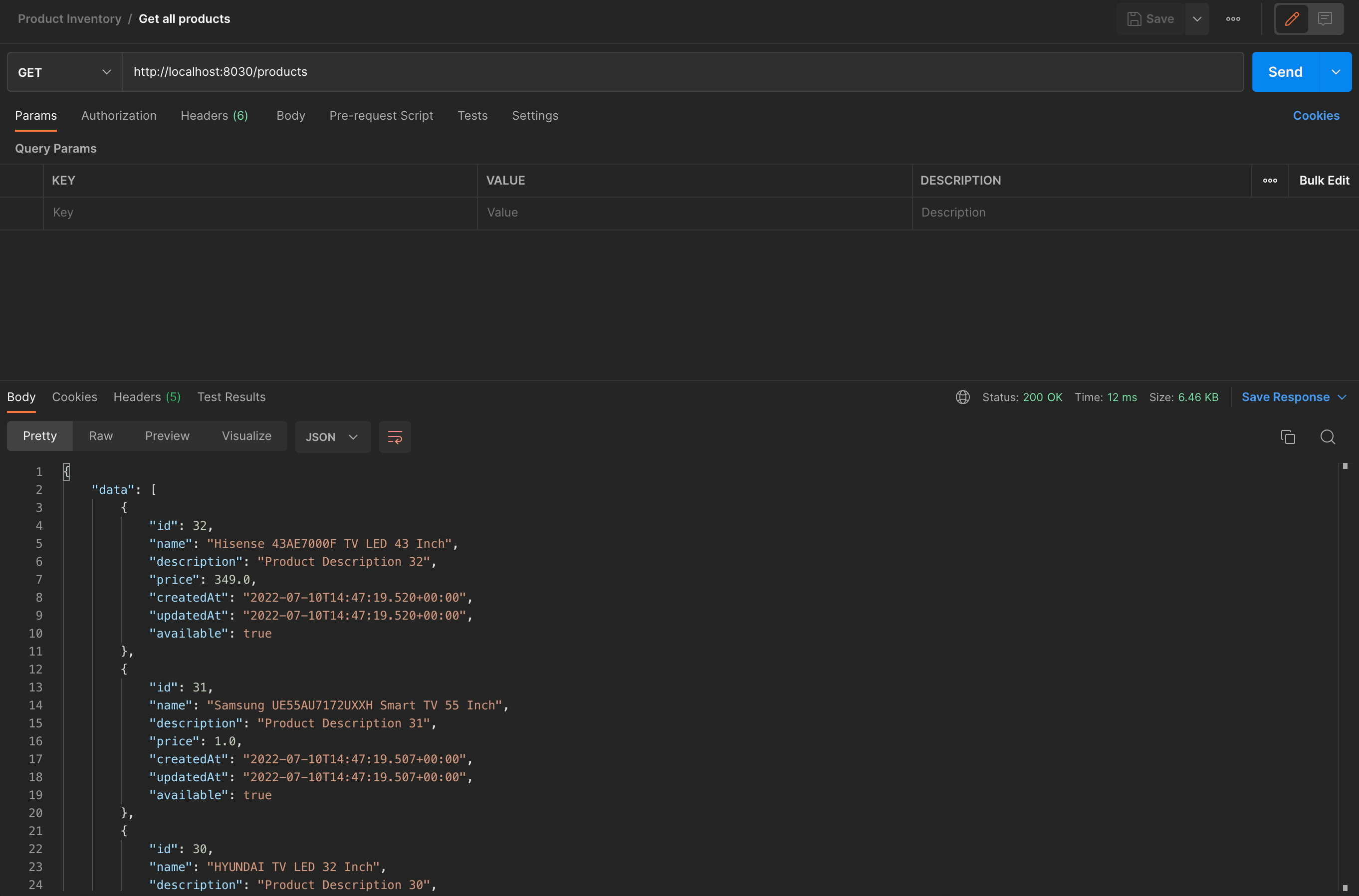
As we can see, the first response was slow, but the next one was very fast ⚡
Cache the route /products/search
The route /products return the same data every time we call it, but with this route, the result varies depending on the query parameters value.
If you find the product named "iPhone" in the category "Phone", you get three results (I built the dataset ?), but if you change the category to "Computer", you get no result.
To have a cache key unique, you must concatenate the values of all the query parameters.
Update the function of this endpoint in the file product.controller.ts:
export const searchProducts = async (req: Request, res: Response) => {
const { available, category, maxPrice, minPrice, name } = req.query as ProductSearchQuery;
const cacheKey = buildSearchProductsCacheKey('searchProducts', {
available,
category,
maxPrice,
minPrice,
name,
});
const rawCachedData = await redis.get(cacheKey);
if (rawCachedData) {
const cachedData = JSON.parse(rawCachedData) as Product[];
return res.json({ data: cachedData });
}
await sleep(3000);
const result = await prisma.product.findMany({
where: {
category: category ? { name: category } : undefined,
isAvailable: available !== undefined ? available === 'yes' : undefined,
name: name ? { contains: name } : undefined,
price: {
gt: minPrice !== undefined ? +minPrice : undefined,
lt: maxPrice !== undefined ? +maxPrice : undefined,
},
},
});
redis.set(cacheKey, JSON.stringify(result));
return res.json({ data: result });
};Here is the function code to build the cache key in the filed utils/cache.ts:
type ProductSearchQuery = {
name: string;
category?: string;
minPrice?: string;
maxPrice?: string;
available?: string;
};
export const buildSearchProductsCacheKey = (keyPrefix: string, searchQuery: ProductSearchQuery) => {
const { available, category, maxPrice, minPrice, name } = searchQuery;
const keyParts: string[] = [keyPrefix, '-', name];
[category, minPrice, maxPrice, available].forEach((criteria) => {
if (criteria) {
keyParts.push('-', criteria);
}
});
return keyParts.join('');
};
Re-run the application and test the endpoint:
Cache invalidation
There are only two hard things in Computer Science: cache invalidation and naming things. — Phil Karlton
Now we have improved request-response time and reduced the database load, we have an issue with data consistency. Once a request is cached, the other's request will get the cached data even if the data are updated (new product, product price update, product delete, etc...).
We must define a way to delete the content in the cache based on some action.
For the route /products, if we add, update or delete a product, we must delete the cache key allProducts in Redis. It is done with the method delete() from the ioredis object:
import { redis } from '../utils/redis';
// add this line after the creation, update or deletion of a product
redis.delete("allProducts");
For the route /products/search, it is tricky. The cache key is generated dynamically; hence we can't guess which one to delete. Every time we add, update or delete a product, the product category is updated, so deleting all the keys that contain this category will enable the system to respond with updated data.
- If we update the price of a product, we delete the key containing the category name of the former.
- If we add a new product, we delete keys containing the category name
- If we delete a product, we delete keys containing the category name
The Redis interface provides a function hkeys() to find all keys containing a specific string.
We can use it like this:
// Find all keys containing the category "Phone"
const cacheKeys = await redis.hkeys('Phone');
// Delete the cached data
await redis.del(cacheKeys);
Another alternative
You can cache data with a Time To Live (TTL). For example, if you set the TTL to 60 seconds, the cached data will be deleted from the cache after this time.
The main benefit is to avoid adding cache invalidation statements everywhere you mutate data. The disadvantage of this solution is that your user will have inconsistent data for a short time.
Wrap up
Caching is the solution to improve the performance of your application and save you a ton of money if applied at the right moment on the correct data.
You can find the code source on the GitHub repository.
Follow me on Twitter or subscribe to my newsletter to avoid missing the upcoming posts and the tips and tricks I occasionally share.