
How to scrape amazon.com with Node.js


In the modern era of digital advancements, acquiring the skills to efficiently scrape Amazon can significantly impact businesses and individuals. As e-commerce behemoths like Amazon continue to dominate the online shopping realm, staying ahead of the competition requires harnessing the power of data.
By becoming proficient in Amazon scraping, you can unlock invaluable insights into product details, monitor pricing trends, and stay abreast of the latest customer reviews. This knowledge can be a game-changer, empowering you to make informed decisions and stay ahead of the curve in the ever-evolving world of e-commerce.

In this all-encompassing guide, we will explore the advantages of utilizing Nodejs for scraping Amazon, showcasing how you can extract vital information to support informed decision-making in your business and personal endeavors.
If you want to scrape it using Python, check out this tutorial by Scrapingdog on scraping Amazon with Python.
Get ready to unveil the hidden insights of Amazon data and tap into the potential of Node.js to stay ahead in the dynamic and constantly evolving realm of the e-commerce.
Setting up the prerequisites
I am assuming that you have already installed Node.js on your machine. Read this guide about installing Node.js. Apart from this, we will require two third-party libraries.
- Unirest- With this library's aid, we will establish an HTTP connection with the Amazon webpage, allowing us to retrieve the raw HTML from the desired target page.
- Cheerio- This robust data-parsing library is instrumental in extracting the essential data from the raw HTML obtained using the unirest library.
Before we install these libraries, we must create a dedicated folder for our project and initialize the Node.js project.
mkdir amazonscraper
npm init -y
We will have to install the above two libraries in this folder. Here is how you can do it.
npm install unirest cheerio
Now, you can create a Node.js file by any name you wish. This will be the main file where we will keep our code. I'm naming it amazon.js.
touch amazon.js
Downloading raw data
Let's make a GET request to our target page and see what happens. For sending GET requests, we are going to use the unirest library.
const cheerio = require('cheerio')
const unirest = require('unirest');
async function amazon(){
const amazon_url = "https://www.amazon.com/dp/B0BSHF7WHW";
const head = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36"
};
const data = await unirest.get(amazon_url).headers(head)
return { message:data.body };
}
amazon().then((data) => {
console.log(data.message);
});
Here is what we have done:
- We imported both the libraries that we downloaded earlier.
- Then inside
amazon()function, we declared the target Amazon URL and headers. - Then we made a GET request using unirest to the target page.
- Then we return the results from where the function is called.
Save and run the code with the following command node amazon.js
Once you run this code, the complete raw HTML of the Amazon page URL will be printed in your console.
What information will we be extracting?
Planning ahead and determining the specific data to be extracted from the target page is a prudent approach. This enables us to proactively analyze the placement of various elements within the Document Object Model (DOM) to streamline the extraction process.
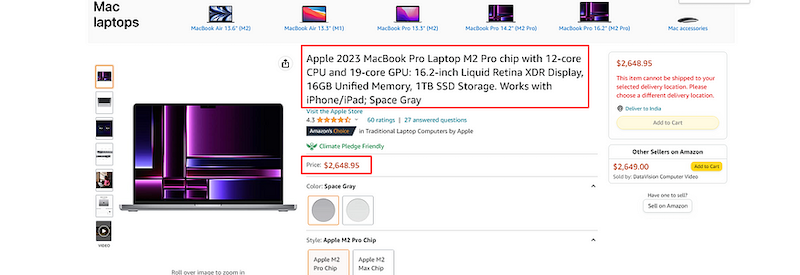
For this tutorial, we are going to scrape two things:
- Title of the product
- Price of the product
But before we start, let's examine the location of each of these elements in the DOM.
Identifying the location of each element
Let's first find where the title's tag is stored in the DOM.

Once you inspect the title, you will find the title text inside the h1 tag with the id title.
Here we will use Cheerio to get the text out of the raw data we downloaded earlier. We will update the code of the amazon.js to add the code below:
// previous code here...
const result = {};
amazon().then((data) => {
const $ = cheerio.load(data.message);
$('h1#title').each((i,el) => {
result.title = $(el).text().trim();
console.log(result.title);
});
});
This Node.js code snippet uses the Cheerio library to load the body of an HTML document stored in the data object. It then selects all the <h1> elements with the id attribute set to "title" using the $('h1#title') selector.
For each of these selected elements, the code executes a callback function (i,el) => {...} using the .each() method. In this callback function, it retrieves the text content of the selected <h1> element using $(el).text(), and trims any leading or trailing whitespace using .trim().
Finally, it assigns the extracted text content to a property named "Title" in an object named result using result.title = $(el).text().trim(). The resulting object result would contain the extracted text content from the <h1> element with the id "title" in the HTML document.
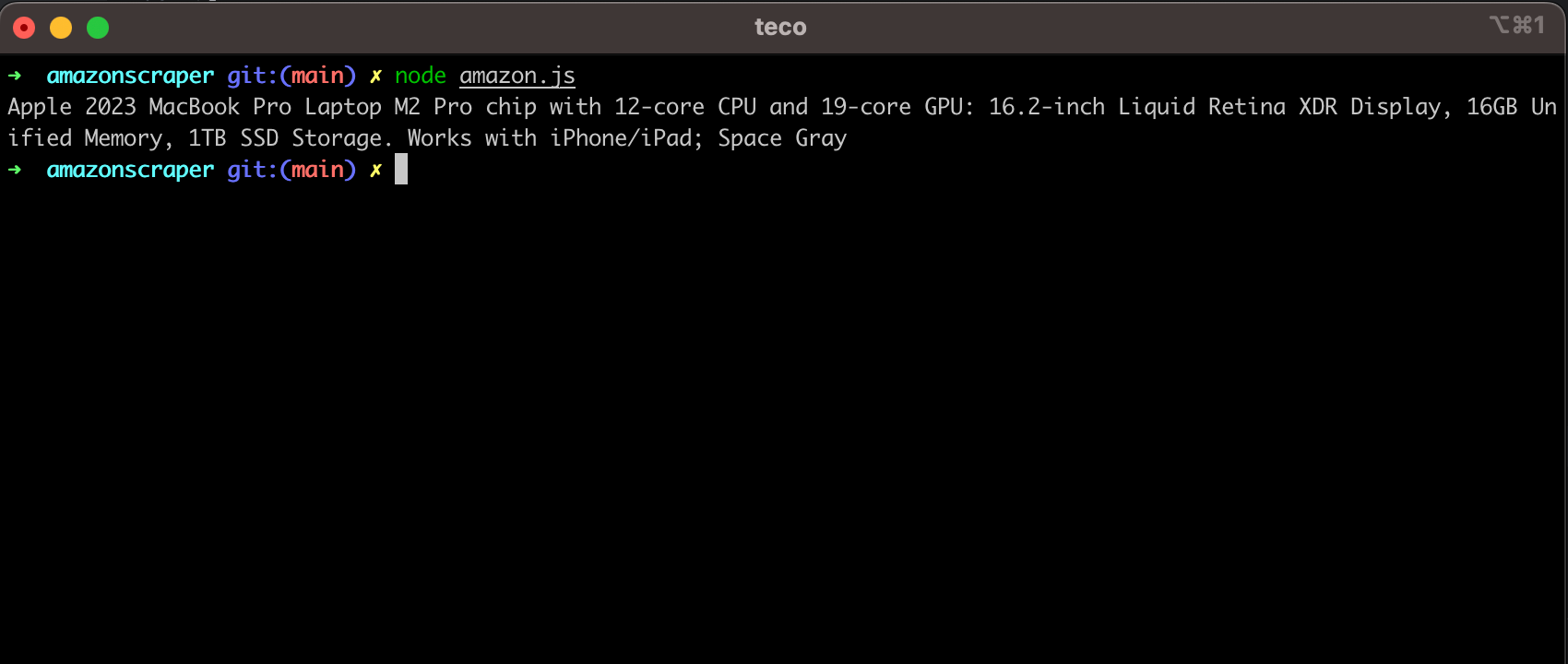
Rerun the code, and you will see the following output:
Now, let's find the location of the price tag.
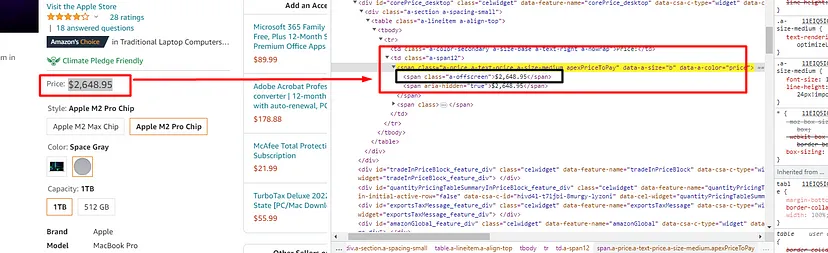
Here is how you can do it. We can see that the price tag is stored inside the span tag with class a-price. Once you find this tag, you can find the first child span tag to get the price.
// Previous code here...
$('span.a-price').each((i,el) => {
result.price = $(el).find('span').first().text();
});
This code snippet uses jQuery syntax with the Cheerio library to select and iterate over all the elements with the class "a-price" in an HTML document.
For each selected element, the code executes a callback function (i, el) => {...} using the .each() method. In this callback function, it finds the first <span> element within the selected element using $(el).find('span').first(), and retrieves the text content of that element using .text().
Finally, it assigns the extracted text content to a property named "price" in an object result using result.price = $(el).find('span').first().text(). The resulting object result will contain the extracted text content from the first <span> element with the class "a-price" in the HTML document, which is typically used for extracting prices of products listed on a Web page.
We have finally managed to find and extract data from the Amazon page. Let's run the code and see what output we get.
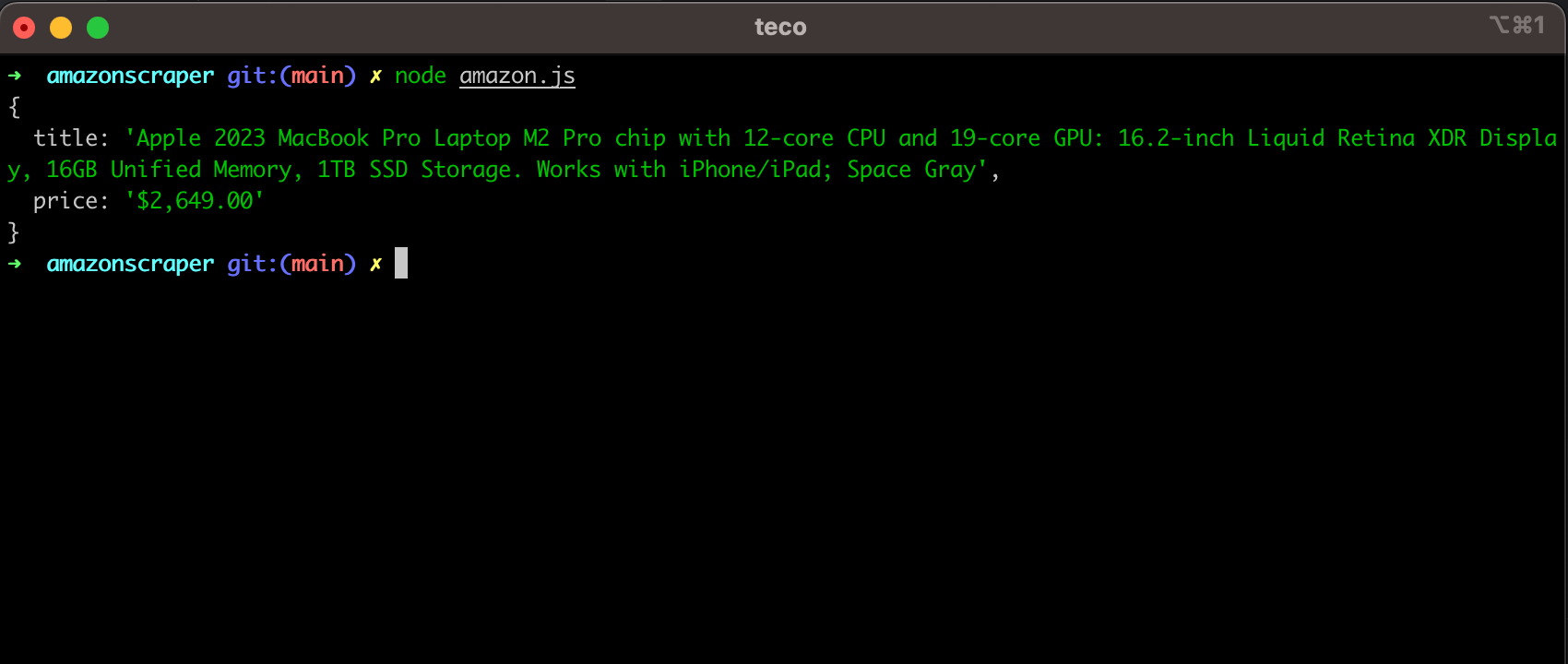
Complete Code
You can scrape many more things from the page, like images, overviews, etc. But for now, the code will look like this.
const cheerio = require('cheerio')
const unirest = require('unirest');
async function amazon(){
const amazon_url = "https://www.amazon.com/dp/B0BSHF7WHW";
const head = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36"
};
const data = await unirest.get(amazon_url).headers(head);
const $ = cheerio.load(data.body);
const result = {};
$('h1#title').each((i,el) => {
result.title = $(el).text().trim();
});
$('span.a-price').each((i,el) => {
result.price = $(el).find('span').first().text();
});
return { message: result };
}
amazon().then((data) => {
console.log(data.message);
});
You can find the code source for the whole project on the GitHub repository.
Conclusion
In this tutorial, we explored scraping data from Amazon using Node.js. We started by using the Unirest library to download the target page's raw HTML and then used Cheerio to parse the data we needed.
Node.js and its various libraries make Web scraping easy, even for beginners. As your scraping needs grow, you can consider using Web scraping APIs to handle large-scale data extraction from multiple pages.
To further enhance the scalability of your scraper, you can combine requests with Scrapingdog, which can provide a success rate of over 99% when scraping Amazon.
Scrapingdog also provides a dedicated Amazon Scraper API that gives the output data in JSON format.
Follow me on Twitter or subscribe to my newsletter to avoid missing the upcoming posts and the tips and tricks I occasionally share