
Manage your Docker container with Docker Swarm


Photo by Manuel Nägeli / Unsplash
Docker Swarm is a container orchestration tool that allows you to manage multiple Docker hosts and deploy containers across them. It is a native clustering tool that can turn a group of Docker engines into a single, virtual Docker engine.
Docker Swarm provides load balancing, service discovery, and scheduling features. With Docker Swarm, you can easily manage and deploy your applications across a cluster of Docker nodes.
Why do you need it?
With Docker and Docker-compose, you can deploy a complete web application requiring many containers on a single VM. As the load received by the application grows, you must increase the VM resources (CPU, RAM, Storage, etc..) to handle it, aka Vertical scaling.
The problem is you can't vertical scale a VM infinitely, so at some point, you will need to deploy the same application on many VMs and balance the load to all the application instances running in these VMs. How could you achieve this?
How Docker Swarm works?
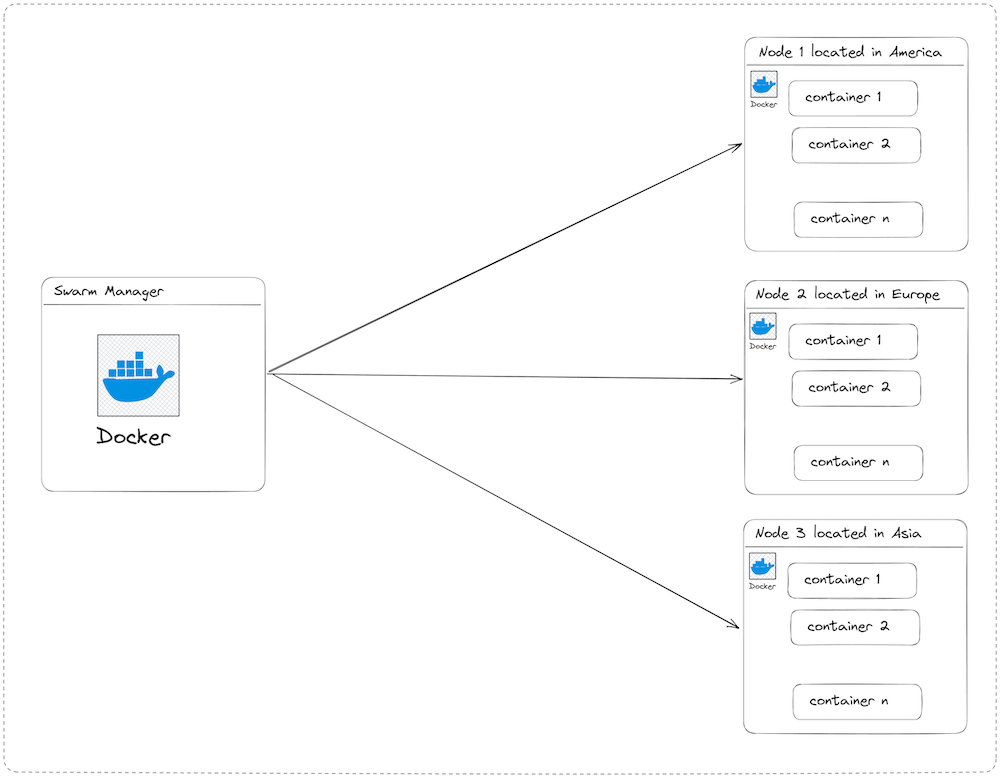
Docker Swarm is built on top of the Docker engine and uses the same API, which means you can use Docker commands to interact with a Swarm cluster. Docker Swarm uses a manager-worker architecture.
The manager node is responsible for managing the cluster and scheduling tasks, while the worker nodes are responsible for running the containers. Docker Swarm uses a swarm mode to manage the cluster, which allows you to define services, networks, and volumes that can be used by the containers.
Prerequisites
To follow this tutorial, you will use a Virtual Private Server running on Ubuntu 20.04 or higher with the minimum requirements of 2 CPUs, 4GB of RAM, and 20GB of storage.
You can buy a VPS on Hetzner, which provides affordable servers with good performance. The server running this blog and all my side projects are hosted here. Use my referral link to get €20 after you sign up.
Once bought the server, you must set up some basic configuration on it. I wrote a whole blog post you can follow.

Install the Docker Engine
We will first install the Docker engine responsible for building, running, and publishing containers. Run the following commands to install it on your server:
sudo apt update
sudo apt install ca-certificates curl gnupg lsb-release -y
sudo mkdir -m 0755 -p /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin -y
Verify that the Docker Engine is installed by running the hello-word image:
sudo docker run hello-world
To run Docker without adding the keyword sudo, you must add the current user in the docker group using the following command:
sudo usermod -aG docker ${USER}
Logout the server and log in again, then run su - ${USER}and enter your password.
Initialize Docker swarm
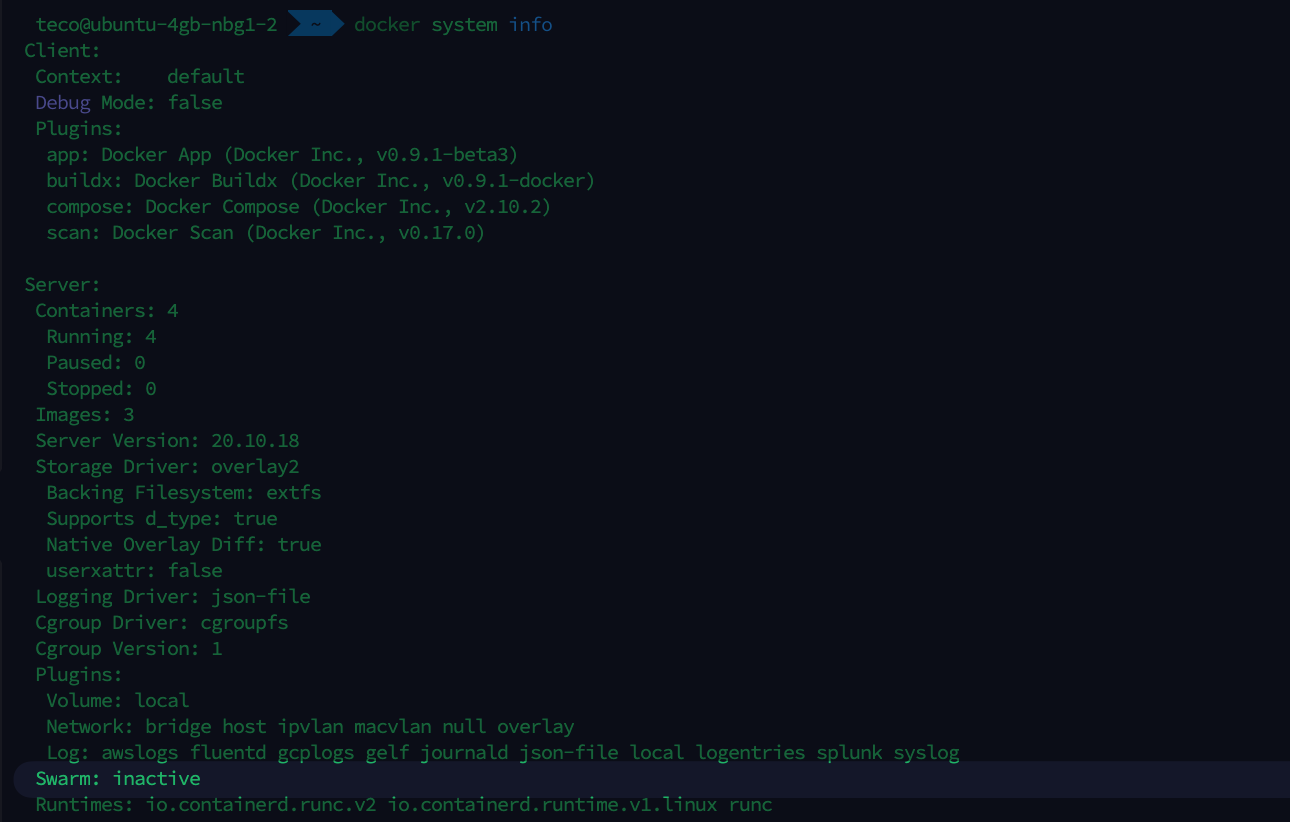
Docker Swarm is not enabled by default; you can run the command docker system info to verify his status.
Run the command below to enable it:
docker swarm init
Swarm will initialize and define the current node (server) as the manager. The output will print the command to add a worker node to the Swarm, but we will not use it this post because we will deploy our application on the manager.
If you want to see how to work with the worker node, let me know 😉.
Write the stack definition of the application
Swarm uses a configuration file written YAML to manage your Docker container. The content of the configuration is similar to the Docker-compose syntax, with some additional properties that give Swarm another capability.
We will use the Docker image of the application we built in the tutorial below, where I show how to configure a load balancer with Nginx. The Docker image is stored on my personal Docker Hub.

We want to start two containers for our backend application; create a file named backend-stack.yaml and add the code below:
version: "3.9"
services:
api:
image: tericcabrel/nodelb-app:latest
networks:
- backend-app-net
deploy:
replicas: 2
mode: replicated
restart_policy:
condition: on-failure
networks:
backend-app-net:
external: true
We create a service with the name api that will start a container from the Docker image tericcabrel/nodelb-app:latest. The container will be linked to an external network named backend-app-net.
For this Docker container, we want to create two replicas, and for each replica will restart if the application running in the container crashes.
About the Swarm mode, there are possible values: global and replicated. The value global means Swarm will create precisely one container per physical node while replicated allow running many containers on the same physical node.
Since the network is marked as external, it means it should already exist when deploying the stack; let's create it using the command below:
docker network create traefik --scope=swarm --attachable
The option --scope allow the network to be used in Docker Swarm. The option --attachable will enable you to manually attach a container to the network.
Run the stack definition
To run the stack, here is the template on the command:
docker stack deploy -c <stack_filename>.yaml <stack_name>
The command to run the stack will be:
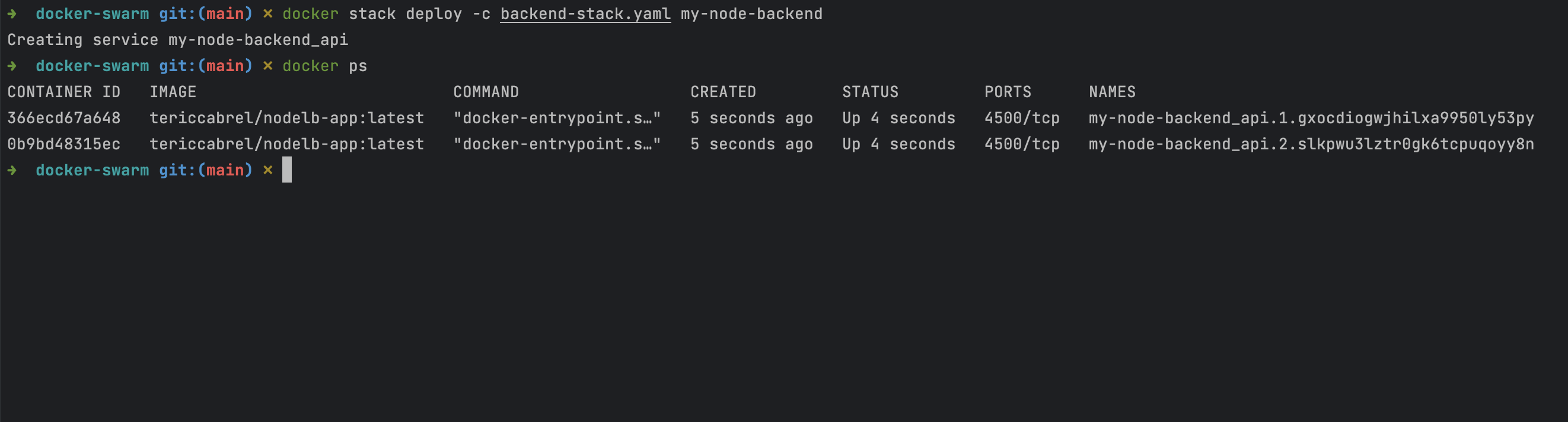
docker stack deploy -c backend-stack.yaml my-node-backend
This command will start two Docker containers of the image; you can run docker ps to view them.
Inspect the stack
When the stack is deployed, you might want to know the states for a specific container. This is possible by inspecting the stack of the application using the command:
docker stack ps <your-stack-name>
We gave the name node-backend-api to our stack.

Other Swarm properties
You can define two properties in your stack configuration file to customize how you want to run your containers, such as limiting the resource to allocate and running a container only if some conditions are met.
The property "resources"
This property allows you to define the minimum physical resource capacity required to run the container and the ability to not exceed it. These are designated with two sub-properties reservations and limits.
On our stack, we can update it with the following code:
version: "3.9"
services:
api:
image: tericcabrel/nodelb-app:latest
networks:
- backend-app-net
deploy:
replicas: 2
mode: replicated
restart_policy:
condition: on-failure
resources:
limits:
cpus: '1'
memory: 500M
reservations:
cpus: '0.50'
memory: 250M
networks:
backend-app-net:
external: true
So here, the container requires at least 250MB of RAM and 0.5 CPU to run and cannot exceed 500MB and 1 CPU.
If the container reaches the maximum capacity and needs more, the service provided to the user by this container will face degradation and possibly crash.
The property "placements"
This property specifies constraints for the platform to select a physical node to run service containers.
- Do you have a service that can only be run on Linux?
- A service must run only on the manager node?
You can use this property to define that. We use the sub-property constraints to describe what is required to run the service.
Our stack will look like this now:
version: "3.9"
services:
api:
image: tericcabrel/nodelb-app:latest
networks:
- backend-app-net
deploy:
replicas: 2
mode: replicated
restart_policy:
condition: on-failure
resources:
limits:
cpus: '1'
memory: 500M
reservations:
cpus: '0.50'
memory: 250M
placement:
constraints:
- node.platform.os == linux
- node.role == manager
networks:
backend-app-net:
external: true
There is another sub-property preferences that define what is nice to have for the service to work seamlessly.
Delete a stack
Deleting a stack stops all the running containers and deletes them. Use the command below our stack:
docker stack rm my-node-backend
Wrap up
With Docker Swarm, you manage the containers running on many nodes, which are physical servers located anywhere in the world. Among all the nodes, one acts as the manager and orchestrates the stack deployed on worker nodes.
Leveraging this technology is crucial when the number of containers required to handle your application load cannot be run on a single node. This will even allow you to predict your scaling needs and act accordingly.
You can find the code source on the GitHub repository.
Follow me on Twitter or subscribe to my newsletter to avoid missing the upcoming posts and the tips and tricks I occasionally share.