
How to Scrape Zillow using Node.js


Photo by Joshua Woroniecki / Unsplash
Analyzing property data before buying or selling any property in any area has become very common. We look at what prices properties are available in an area, their size, the size of the road in front of the house, etc.
After this analysis, we make our own conclusion. Since a vast amount of data is available on the internet, it has become time-consuming to copy and paste the data usually.
This is where web scraping can help you extract data in no time. In this tutorial, we will scrape property data from Zillow that is available for sale. For this, we will use Nodejs.
Why Scrape Zillow?
There are several reasons why someone might want to scrape Zillow’s website. Some potential reasons could include the following:
- Real estate professionals or investors may want to gather data on current or past listings in a specific area to make informed decisions about buying or selling properties.
- Researchers or analysts may want to study trends in the real estate market by collecting data on listings and sale prices over time.
- Data enthusiasts may be interested in using Zillow’s data for personal projects or building tools and applications for others.
- Zillow’s data may also interest journalists or bloggers looking to write about the real estate market or specific properties.

Prerequisites
To follow this post, you will need to install this tool on your computer:
- Node.js 16 or higher - download's link
- NPM - It comes with Node.js
Set up the project
Let's a new Node.js project in which we will write the code to scrape Zillow:
mkdir node-scrape-zillow
cd node-scrape-zillow
npm init -y
touch index.js
We set up the project using JavaScript; if you want to set up a Node.js project using TypeScript, I wrote a blog post about it.
Scraping Zillow with Node.js
First, you will need to install two node package dependencies.
- Unirest or Axios to make HTTP requests to the Zillow website.
- Cheerio or Puppeteer to parse the HTML response and extract your desired data.
For this tutorial, we are going to use Unirest and Cheerio.
Cheerio
Cheerio is a fast, flexible, lean implementation of core jQuery designed specifically for the server. It allows you to use the familiar syntax of jQuery to manipulate the HTML returned by a server and make HTTP requests to servers.
Cheerio is commonly used with Node.js to scrape web pages for data or to manipulate the DOM (Document Object Model) of a web page.
Cheerio is often used with other libraries, such as Unirest, to retrieve and parse the HTML or XML from a web page. Once the HTML or XML is loaded into Cheerio, you can use its methods to select and manipulate elements, extract data, and perform other operations.
npm install cheerio
Unirest
Unirest is a lightweight HTTP request library for Node.js. It lets you send HTTP requests to servers using a simple, easy-to-use API. Unirest supports a wide range of HTTP methods, including GET, POST, PUT, PATCH, DELETE, HEAD, and support for custom methods. It also allows you to send and receive JSON and XML data and form data.
npm install unirest
Implementation
We will use this URL as our target webpage. We will make a GET request to this page using unirest and check the status code; if it is 200, we parse the data using Cheerio. We will extract the following data from the web page:
- Price
- Address
- Bedroom
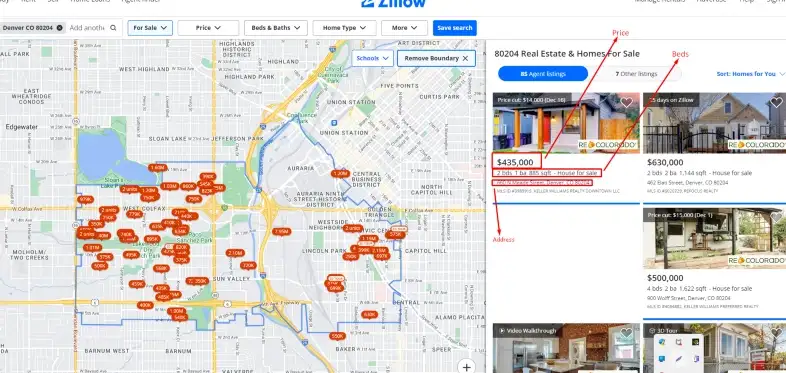
Next, you must send the HTTP request to the webpage using unirest and check for the status code.
const unirest = require('unirest');
async function zillow() {
const target_url = "https://www.zillow.com/homes/for_sale/";
const zillow_data = await unirest.get(target_url);
return zillow_data.body;
}
zillow().then((data) => {
console.log(data);
});
We have created an asynchronous function named zillow() that makes an HTTP connection to the target URL.
The next step will be to check whether the response status code is 200. The status code 200 will confirm a successful HTTP connection to the host website.
const unirest = require('unirest');
async function zillow() {
let target_url="https://www.zillow.com/homes/for_sale/";
let zillow_data = await unirest.get(target_url);
const $ = cheerio.load(zillow_data.body);
if (zillow_data.statusCode === 200) {
$('.list-card-info').each(function() {
const price = $(this).find('.list-card-price').text();
const address = $(this).find('.list-card-addr').text();
const bedrooms = $(this).find('.list-card-details li:nth-child(1)').text();
console.log(price, address, bedrooms);
});
}
}
zillow();
In the example above, cheerio.load() it is used to parse the HTML string and create a new Cheerio object. This object has a similar interface to the $ object in jQuery and can be used to select and manipulate elements in the HTML document.
Execute the data scraping
This code can help you scrape all the property data from Zillow, but if you run the code using the command node index.js, you will get no result from the scraping.
If we console.log() the content of the variable zillow_data, we can see that we got HTML content, but not the one we expected.
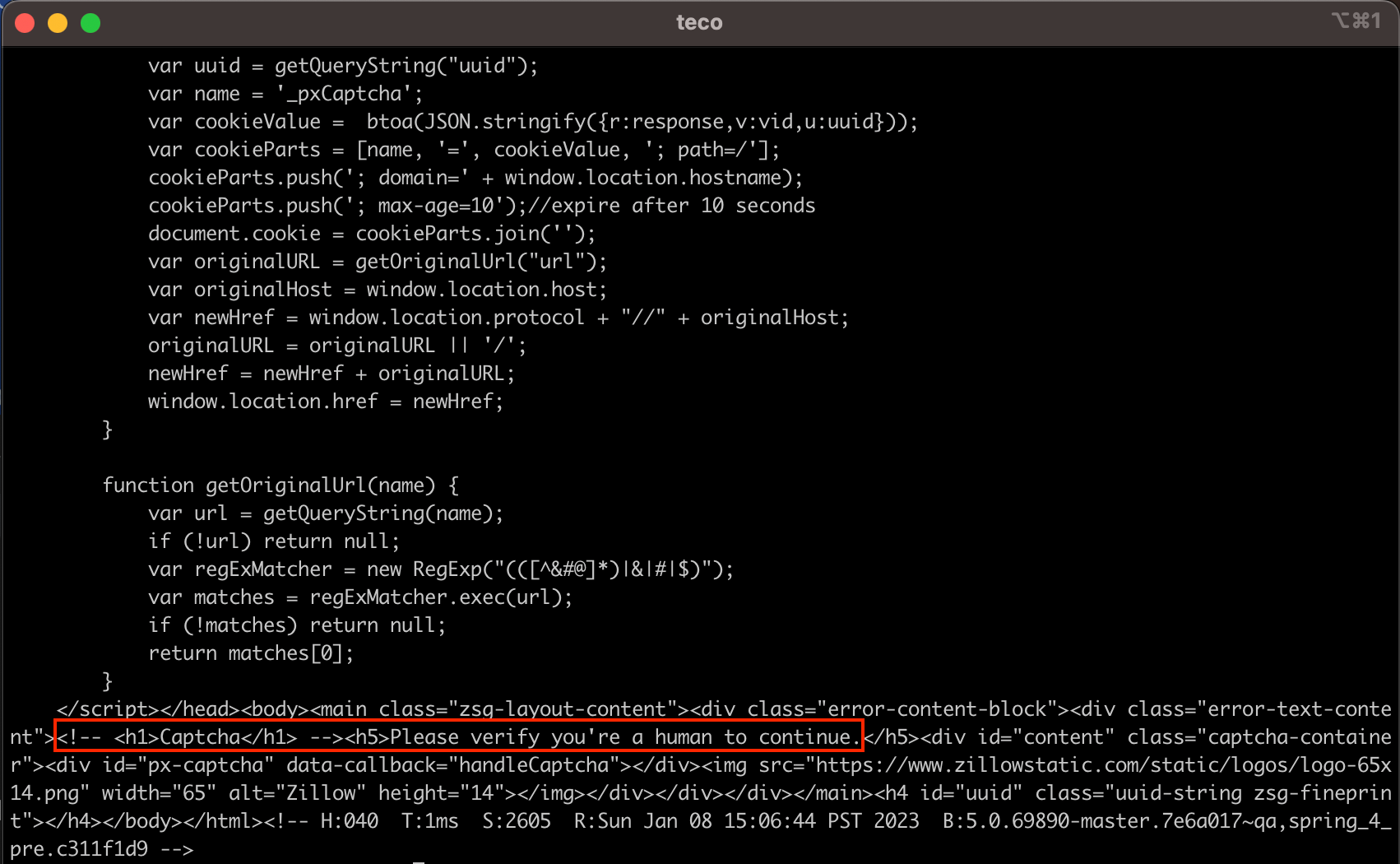
We need a more sophisticated tool to bypass the captcha verification to get the data we need to solve this issue. This tool can be software or an online service like Scrapingdog that provides a Web scraping API with enhanced features. We will use Scrapingdog’s Web Scraping API in the next step.
Using Scrapingdog to scrape Zillow
With the method used above, you cannot scrape Zillow at scale. Zillow uses top-level data protection tools to prevent scraping.
So, if you make bulk calls to Zillow, you will get blocked. This is where Scrapingdog can help you.
Scrapingdog is a Web Scraping API that rotates IPs on every new request. It uses headless chrome to scrape any website without getting blocked.
They recently updated and added a dedicated Zillow Scraper API.
Let’s see how to scrape Zillow with Scrapingdog.
Step 1: Register
You have to sign up for the free pack from here. A free pack will provide 1000 free credits, enough to test the service. Once you sign up, you will be redirected to your dashboard, where you will find your API key.
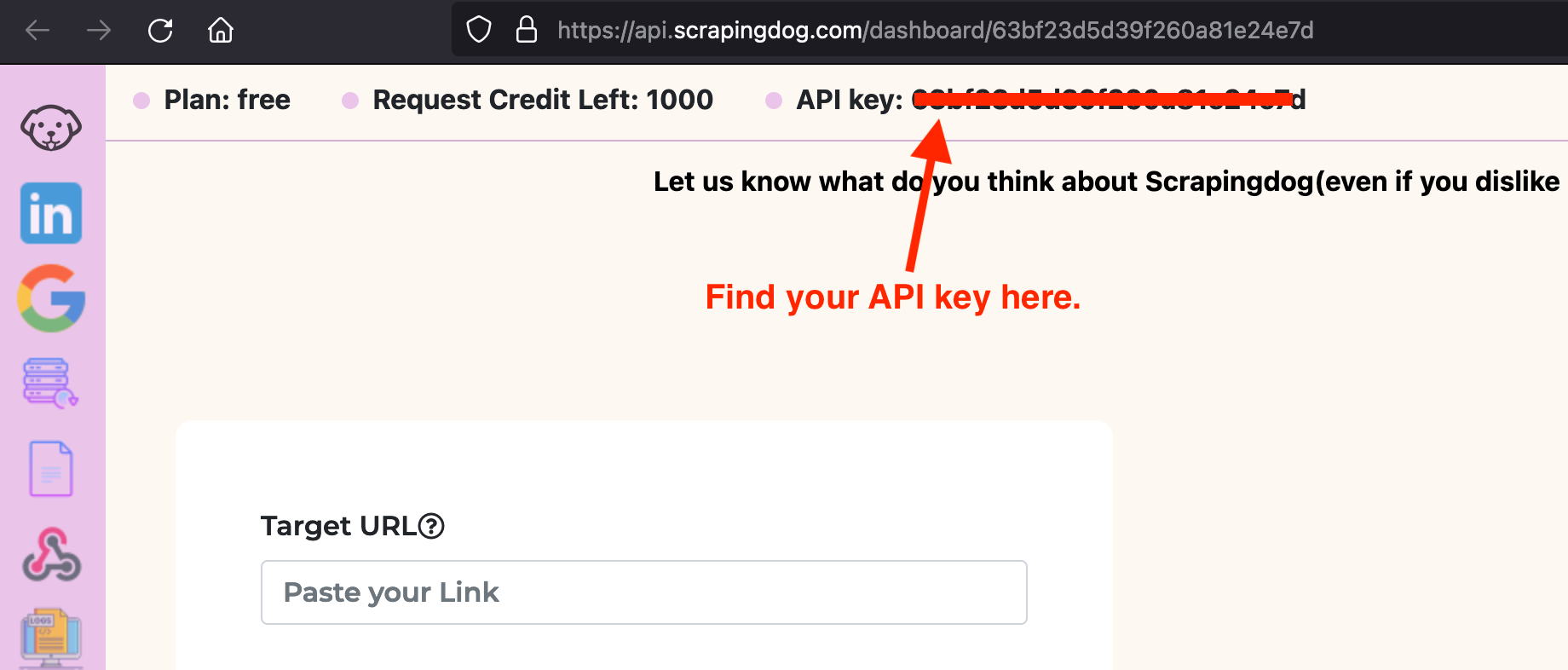
This API key will be used for web scraping in the next step.
Step 2: Scraping
We will update the target URL to use Scrapingdog API and pass the web page to scrape as a query parameter along with the API key. A template of the target URL will look like this:
https://api.scrapingdog.com/scrape?api_key=<your_api_key>&url=<url_of_the_webpage_to_scrape>
Here is the complete code to scrape the data; you can see that not only the target URL changed but also the way to extract data from the HTML content of the page.
const unirest = require('unirest');
const cheerio = require('cheerio');
async function zillow() {
const target_url = "https://api.scrapingdog.com/scrape?api_key=xxxxxxxxxxxxxxxx&url=https://www.zillow.com/homes/for_sale/&dynamic=false";
const zillow_data = await unirest.get(target_url);
const $ = cheerio.load(zillow_data.body);
if (zillow_data.statusCode === 200) {
const housesInfo = [];
$('ul li.with_constellation').each(function () {
const price = $(this).find('span[data-test="property-card-price"]').text();
const address = $(this).find('address[data-test="property-card-addr"]').text();
const bedrooms = [];
$(this).find('span[data-test="property-card-price"]')
.parent().next().children('ul').children('li').each(function () {
bedrooms.push($(this).text());
});
if (!address) {
return;
}
housesInfo.push({
address,
bedrooms: bedrooms.join(' - '),
price,
})
});
console.table(housesInfo);
}
}
zillow();
Execute the code with Node.js by running the command node index.js; we get the following output:
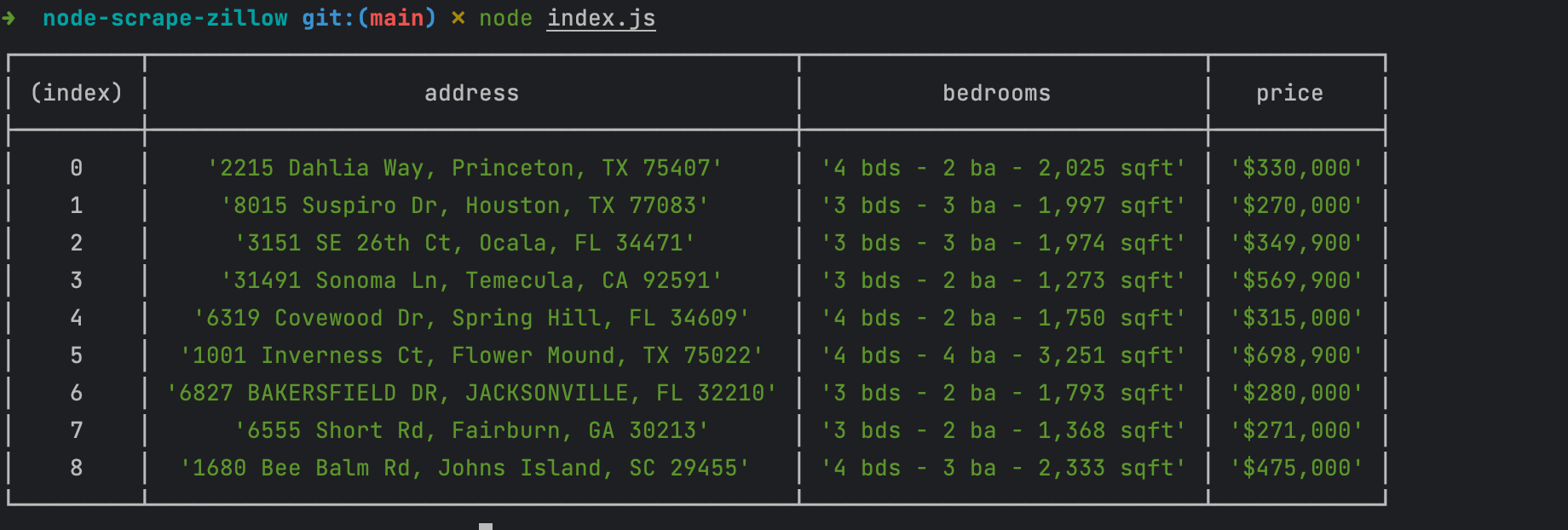
Now, we can get the data without getting blocked by the captcha verification. As we saw above, Scrapingdog can scrape any website without getting BLOCKED.
Conclusion
Zillow is a data-rich website; scraping this website is helpful for data analysis on property data. Nodejs can help you scrape Zillow in no time.
Scraping a website like Zillow is problematic because you will receive captcha validation. With just a few more changes to the code, you can extract a bit more information from Zillow using a web scraping API like Scrapingdog to scrape Zillow at scale without getting blocked.
If you are interested in more website scraping, read about web scraping Amazon.
You can find the code source on the GitHub repository.
Follow me on Twitter or subscribe to my newsletter to avoid missing the upcoming posts and the tips and tricks I occasionally share.